

“I told him ‘Keep running.’ He—and he said, ‘Naw,’ he’ll just walk faster. I’m like, ‘Oh oh.’ And I—I ain’t complain, ’cause he was breathing hard, so I understand why.”
This is how Rachel Jaental described Trayvon Martin’s last conversation before he was killed while she was testifying in the murder trial of George Zimmerman. The case, which became emblematic of the systematic injustices faced by African Americans within the criminal justice system, sparked the first use of the hashtag #BlackLivesMatter, which grew to be an influential movement against racial injustice. Zimmerman was acquitted and the jury disregarded the key prosecution witness Rachel Jaental’s testimony, in part because, as one juror subsequently said in a CNN interview, Jaental was “hard to understand”[i]. Despite being pilloried in social media as stupid or illiterate, Jaental in fact spoke what linguists call African American Vernacular English (AAVE), a dialect with its own syntactic rules which Jaental applied consistently and correctly during her testimony. Nonetheless, being different to Standard American English (SAE), it is often derided as incorrect or uneducated English. And so linguistic variation (and racially-motivated prejudice about linguistic variation[ii]) played a significant and tragic role in this historic trial[iii].
The same problem, of understanding people who use non-standard variants of language, is encountered when trying to build technology that can interact with users in human language. We should strive to build products and services which are maximally accessible, since a company’s customer base will likely span multiple non-standard dialects. You might imagine this would require a costly data-collection procedure, so as to obtain training data that is reflective of the astonishing diversity of language usage. While this may turn out to be true, there are a few tricks that NLP practitioners should be aware of that can help AI learn rare dialects with less need for training data.
What are word vectors?
These tricks revolve around how words are encoded as numeric inputs to an AI model. This is one of the areas of natural language processing which has been transformed the most by the data-mining of huge text corpora (such as all articles on Google News, a news aggregation site, or all of Twitter). This allows words to be identified with points in space, according to what linguists call the distributional hypothesis: words which regularly occur in the same context should be represented by nearby points, and hence have similar meanings. For instance, consider the word nurse. We are going to assign nurse a set of coordinates of dimension (length) equal to the number of words in our training dataset (which could be many hundreds of thousands or even millions), by setting the ith coordinate to be the number of times the ith word in our training data is observed less than three[iv] words apart from the word ‘nurse’ in our training data. What can we expect? Well, the words ‘a’ and ‘the’ will be seen very frequently near ‘nurse’, because of occurrences of ‘a/the nurse.’ But this would be true of any singular noun; thus we can identify ‘nurse’ as a singular noun (a piece of syntactic information about the word) by observing a high coordinate in the a-axis and the the-axis. Common words, such as ‘and’ will occur in the contexts of many words merely because they are common, so although we can expect a high coordinate for ‘nurse’ in the and-axis, this does not contribute to our knowledge of the word. We can also expect words such as ‘hospital’, ‘doctor’ and ‘medicine’ to occur frequently near to ‘nurse’ and thus the count-based coordinates contain information about the semantics of the word. Crucially, however, we do not say the words ‘hospital’ and ‘nurse’ are similar because ‘nurse’ has a high coordinate in the hospital-axis. By the same logic, we would conclude bizarrely that ‘nurse’ and ‘the’ are similar, and that synonyms are often somewhat dissimilar (an author is unlikely to use the words ‘annoyed’ and ‘irritated’ together since this would be repetitious). Instead, we say the words ‘hospital’ and ‘nurse’ are similar because when you consider all the contexts ‘nurse’ occurs in and all the contexts in which ‘hospital’ occurs, you find yourself looking at a similar collection of contexts – or equivalently, the set of coordinates corresponding to the word ‘nurse’ and the set of coordinates corresponding to the word ‘hospital’ represent points that are close together in terms of geometric distance.
In principle, the coordinates we have just defined constitute what is called a word vector, but in practice feeding vectors whose dimensionality is of order 105 or 106 into an AI model would make any processing or manipulation so computationally expensive as to render it infeasible. To solve this, a mathematical technique called dimensionality reduction can be applied. For present purposes, the details of this are unimportant, and the reader may safely accept that this is a process that for each word replaces the high dimensional coordinates we just created with summaries consisting of just a few hundred numbers, in such a way that as much as possible of the linguistic knowledge encapsulated by the geometry of the original coordinates are retained in the geometry of the summary coordinates. When reasoning about word vectors it is often helpful to think about the pre-dimensionality reduced coordinates, and trust that whatever conclusions you reach remain true after dimensionality reduction is applied[v].
It is true and noteworthy that it is not merely the distances between word vectors which contain linguistic knowledge, but also the directions in which the word vectors differ. For example, the following equation holds in most commonly used sets of trained word vectors:
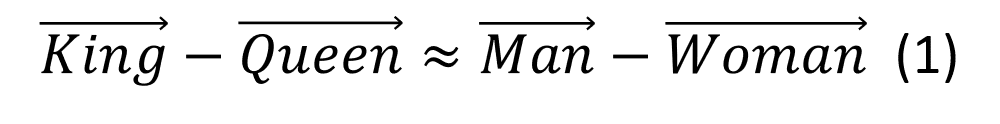
The above equation should be read as follows: if you are standing at the point whose coordinates correspond to the word ‘king’ the bearing you would have to take to travel in the direction of the point corresponding to ‘queen’ is (almost) the same as the bearing you would take to go from ‘man’ to ‘woman.’ It is easy to gain an intuition for why this equation holds as follows: many words will occur in the context of both ‘king’ and ‘queen’, so we can expect the vectors for ‘king’ and ‘queen’ to have similar coordinates in the crown-axis, coronation-axis, reign-axis etc. However, we can reasonably expect that ‘king’ would have a higher coordinate (compared to ‘queen’) in the manservant-axis or even the wife-axis, whereas ‘queen’ would have a higher coordinate in the lady-in-waiting-axis or the husband-axis. The coordinates of the words ‘man’ and ‘woman’ will similarly differ in the manservant, lady-in-waiting, wife, husband-axes, and hence the equation holds. This is all very well so far, but there are other equations which hold which have more troubling consequences:
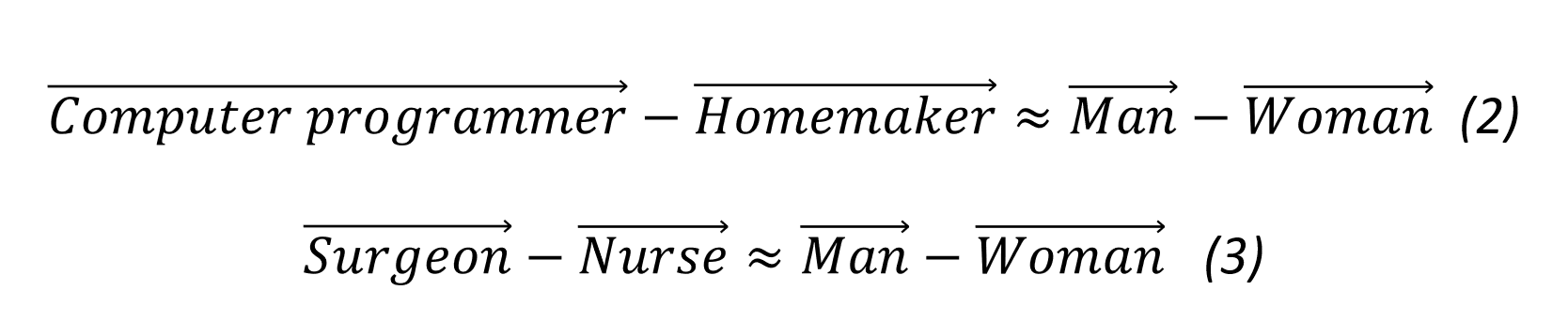
Gender bias in word vectors
Amazon recently disbanded its efforts to build an AI-powered hiring tool designed to suggest a few suitable candidates for a job opening from a large collection of CVs, after it demonstrated a bias against female candidates[vi]. The AI apparently learned to penalise candidates who used the word ‘women’s’ in their CV, for instance in phrases such as ‘I was captain of the women’s chess club’ or ‘I attended a women’s college.’ It is easy to see how this could be another manifestation of the same phenomenon that underlies the sexist word associations summarised by equations 2 and 3. An AI that understands ‘computer programmer’ to be more similar to ‘man’ than ‘woman’ would favour people who include the words ‘man’ or ‘men’s’ in their CV (most likely men) to those who include the words ‘woman’ or ‘women’s’ (most likely women) for the job of computer programmer, because their CVs would be considered more similar to the job description.
Gender bias is present in any language dataset written by humans and has been identified in a range of corpora from unmoderated content such as tweets to, perhaps more surprisingly, articles written by professional journalists and published in respectable media outlets. Indeed, gender distinctions exist in language at the structural level; for example, words such as ‘actor’ or ‘governor’ are by default in their masculine form and need to be marked to be feminised as ‘actress’ or ‘governess.’ Other words which we would like to be gender-neutral (such as ‘computer programmer’) in fact have very gendered word representations, while the differences between pairs of words (for example 'volleyball' and 'football') and may indirectly reflect gender bias, meaning the analogy ‘man is to football as woman is to volleyball’ may be encapsulated in our word vectors.
Fortunately, there is a very simple way that gendered components of word semantics can be removed from our vectors, thereby debiasing them, shown by Bolukbasi et al. in their 2016 paper Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings[vii]. The solution arises from the fact that the distinctions in word meaning that reflect gender bias are encoded in a single direction in our space of word vectors. We can determine this direction by considering the directions between pairs of words which we expect to have the same meaning except for a difference in gender, such as (man, woman), (boy, girl), (he, she), (father, mother), etc. These pairs are called seed pairs, and the average over all seed pairs of the directional differences between the words within a seed pair is taken to be the gendered-axis. This gendered-axis identifies both individual words which are closely associated with a gender or pairs of words whose meanings differ largely due to gender.
To debias our word vectors we might try to completely expunge this gendered-axis by replacing every word’s gendered-coordinate with zero. This however would remove crucial parts of words whose meaning does and should incorporate gender. For example, we want an AI model to be more likely to output the sentence ‘She was a successful businesswoman’ than ‘she was a successful businessman’, but to achieve this we need to retain the gendered-component of businesswoman and businessman. Bolukbasi et al. solve this by training a second machine learning model (in their case a linear support vector machine) which learns to separate genuinely gendered words, such as ‘businesswoman’ from spuriously gendered words due to bias, such as ‘computer programmer’.
This is an extremely tough task for an ML model, since establishing what words should be gender-neutral or not is by no means trivial for humans. Does the equation:
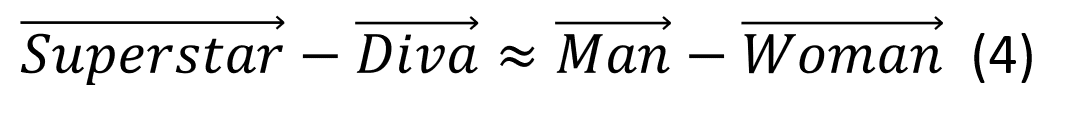
reflect gender bias, or merely the original meaning of ‘diva’ as a celebrated female opera singer? Polysemous words might have gender-neutral and gendered meanings: the profession ‘nursing’ should be made gender-neutral, but ‘nursing’ when used to mean breast-feeding, should not. These issues could perhaps be alleviated by applying this same technique to contextualised word vectors (such as ELMo vectors[viii]) which take into account the specific context in which a word occurs when assigning word vectors. Furthermore, the gender-content of a word and its permissibility may depend on other factors, such as the gender of the author or the intended purpose of the NLP technology. Consider Jane Austen’s description of her heroine Catherine Morland in the opening of Northanger Abbey: “It was not very wonderful that Catherine, who had nothing heroic about her, should prefer cricket, base-ball[ix], riding on horseback, and running about the country at the age of fourteen, to books.” An AI model which is blind to the gendered associations attached to words such as cricket, base-ball or heroic would not grasp the full meaning of this sentence and fail at the task of answering English Literature exam-style questions about Austen’s novels. The fallacy that blindness to racial or gender differences is either readily achievable or desirable (at least at the level of individuals) was borne out in the attempt to supplant the hashtag #BlackLivesMatter with #AllLivesMatter, which has the effect of ignoring the structural disadvantages faced by African Americans. Ideally, AI should understand the human condition sufficiently to be aware of our shortcomings yet be able to transcend our bias when making decisions. This, however, would be a truly superhuman AI, and for narrow applications we will have to satisfy ourselves with AI that has been purposefully blinded to gender and racial distinctions in word meanings according to the described method.
Learning to understand rare dialects
One area where AI agents might surpass humans is the ability to understand dialects of their language which they have not come across regularly – in part because of the human tendency to become frustrated when obliged to strain in order to understand an interlocutor. Philippa Shoemark of Edinburgh University presented a paper which extends the work of Bolukbasi et al. at the 2018 Conference on Empirical Methods in Natural Language Processing, held in Brussels, Belgium, attended by ContactEngine, which addressed part of this challenge[x]. There are words in different dialects of the same language (such as AAVE and SAE) which have the same meaning but different lexical forms – that is to say they are written differently. For example, g-dropping is common in AAVE where words such as ‘getting’ in Standard American English are written ‘gettin’ in AAVE. While this difference could be handled by common NLP algorithms that combine character and word-level inputs, other AAVE/SAE pairs may not be morphologically similar, such as ‘siditty’ being equivalent to ‘snobbish’ in SAE. Just as we defined the gendered-axis in the previous section of this blogpost, Shoemark and her collaborators were able to use a set of seed pairs such as (brother, brudda) and (nothing, nuttin) to define an axis which distinguishes between words which are more typical in SAE and those more typical in AAVE.
Applying this methodology to word vectors trained on data containing a mix of dialects, they were able to retrieve pairs of words that have close word vectors, but which differ primarily along the axis separating the two dialects in question, to form a sort of cross-dialect glossary of words with the same meaning but different forms (see table).
| BrEng / Scottish | BrEng / GenAm | GenAm / AAVE |
| now / noo | mums / moms | the / tha |
| what / whit | dunno / idk | with / wit |
| wasn’t / wis | yeh / yea | getting / gettin |
| cant / canny | shouting / yelling | just / jus |
| would / wid | quid / dollars | and / nd |
| doesn’t / disny | learnt / learned | making / makin |
| cant / cannae | favour / favor | when / wen |
| going / gonny | sofa / couch | looking / lookin |
| want / wanty | advert / commercial | something / somethin |
| anyone / embdy | adverts / commercials | going / goin |
Suppose you want to train a supervised NLP model, for instance a text classifier, which will take inputs in the form of word vectors. If your labelled training data consists of few (or no) examples written in rarer dialects such as AAVE or Scottish English, but your word vectors have been trained on a more representative corpus[xi], and thus have captured directions encoding the difference between dialects, then collapsing your word vectors in these directions will better enable your model to understand lexical variants of words associated with these dialects. Of course, this does not solve the problem entirely. There are other issues that need to be tackled: for instance, the same word may have distinctly different meanings in different dialects. The described method would also not capture syntactic differences between dialects, since the debiasing operates solely at the word-level.
The methods described in this blog clearly do not provide a panacea for every case of AI bias, nor are we likely to find such a thing anytime soon. However, removing implicit biases is a challenge not only for AI, but for us humans too. For us, this requires an uncomfortable probing both of our own psyche and our society to understand the effects and motives of our actions. AI has an easier shortcut: we can identify ‘bias’-directions within how AI encodes information and where necessary remove this information from the AI’s purview. But this is not automatic: it requires data scientists and product owners within tech companies to make difficult decisions about how language should be and should not be understood. It therefore makes such people the jurors in a trial where language itself is defendant, charged with memorialising all of our past and present prejudices.
[i]https://edition.cnn.com/2013/07/15/justice/zimmerman-trial-jeantel/index.html
[ii]https://news.stanford.edu/news/2014/december/vernacular-trial-testimony-120214.html
[iii]Miscarriages of justice caused by a failure to understand dialect or creole forms of language are sadly not rare occurrences. For an overview of the Rachel Jaental case and others, consult ‘Language and linguistics on trial: Hearing Rachel Jeantel (and other vernacular speakers) in the courtroom and beyond’, John R. Rickford, Sharese King, Language, Volume 92, Number 4, December 2016, pp. 948-988
[iv]Three is merely chosen as an example and has no special significance. Choosing the size of the context window is a choice that data scientists have to make when training word vectors.
[v]The presentation of how word vectors are created given here actually differs significantly from how neural word vectors such as the word2vec model an trained in practice, but the properties of the two methods can be shown to be equivalent, see Omer Levy and Yoav Goldberg. 2014. Neural word embedding as implicit matrix factorization. In Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2 (NIPS'14), Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger (Eds.), Vol. 2. MIT Press, Cambridge, MA, USA, 2177-2185. Highlighting how word vectors are a summary of all the contexts in which a word occurs is a good way to gain intuition for various properties of word vectors which seem mysterious when considering the usual presentation of the skip-gram or CBOW models.
[vi]https://www.reuters.com/article/us-amazon-com-jobs-automation-insight/amazon-scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idUSKCN1MK08G
[vii]Bolukbasi, T.; Chang, K.-W.; Zou, J. Y.; Saligrama, V.; and Kalai, A. T. Man is to computer programmer as woman is to homemaker? Debiasing word embeddings. In Advances in Neural Information Processing Systems, 4349– 4357. 2016.
[viii]Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word representations. In Proceedings of NAACL, 2018
[ix]Yes, baseball was in fact commonly played in late 18th Century Britain.
[x]Shoemark, P, Kirby, J & Goldwater, S 2018, Inducing a lexicon of sociolinguistic variables from code-mixed text. in 2018 The 4th Workshop on Noisy User-generated Text (W-NUT): Nov 1, 2018, Brussels, Belgium (at EMNLP 2018). 4th Workshop on Noisy User-generated Text (W-NUT), Brussels, Belgium, 1/11/18.
[xi]Word vectors are trained on unannotated datasets which can therefore be much larger and hence representative than datasets used to train supervised machine learning algorithms.


